ในบทความนี้นะครับเราก็จะมาลองใช้ Machine learning มาอธิบายว่าอะไรที่เป็นปัจจัยที่ทำให้ฝุ่นเพิ่มขึ้นหรือลดลงบ้าง ปกติหลายๆคนอาจจะเข้าใจว่า Machine learning เป็น Black box ไม่สามารถอธิบายการทำงานได้ ซึ่งเป็นความเข้าใจที่เก่าแล้วนะครับ ปัจจุบันมีหลายงานวิจัยที่ตีพิมพ์เกี่ยวกับการอธิบายการทำงานของโมเดล วันนี้เราก็จะมาใช้เทคนิคเหล่านี้และครับในการทำความเข้าใจเกี่ยวกับ PM2.5 แทนที่จะใช้เพื่อการทำนายค่า ต้องบอกก่อนเลยว่าผู้เขียนเองไม่ได้มีความรู้พิเศษทางด้านอุตุนิยมวิทยาหรือฝุ่นแต่อย่างใด การอธิบายและตีความอาจไม่ถูกต้องตามหลักวิชาการครับ
มาลองดูกันครับว่าข้อมูลจะบอก insight อะไรกับเราได้บ้าง
Data
ข้อมูลที่เราใช้ในการเทรนโมเดลก็จะมีมาจากสองส่วนด้วยกันครับ
- Bangkok PM2.5 Data - Berkeley Earth [Link]
- ข้อมูลสภาพอากาศจาก Wunderground.com — สถานีอากาศร.ร.สาธิตประทุมวัน [Link]
สาเหตุที่เลือกชุดข้อมูลนี้เพราะว่าสามารถดึงข้อมูลย้อนหลังรายชั่วโมงได้ถึง 3 ปี แต่ข้อเสียก็คือจุดวัดฝุ่นกับจุดวัดสภาพอากาศอยู่ค่อนข้างที่จะห่างกันครับ อาจจะส่งผลกับความแม่นยำของโมเดลได้ และแน่นอนว่าอาจจะมีข้อมูลอื่นที่ส่งผลกับ PM2.5 นอกเหนือจากข้อมูลข้างต้นอีกมากมายครับ
ข้อมูลอื่นๆที่หาเจอแต่ไม่ได้ใช้
- โครงการศึกษาแหล่งก าเนิดและแนวทางการ จัดการฝุ่นละอองขนาดไม่เกิน 2.5 ไมครอน ในพื้นที่กรุงเทพและปริมณฑล — กรมควบคุมมลพิษ
- Air4Thai.com สรุปข้อมูลคุณภาพอากาศ พ.ศ. 2557–2561
Technique
- เทคนิคในการเทรนโมเดลที่เราใช้ก็จะมีชื่อว่า Gradient Boosted Trees ครับโดยใช้ Library ที่ชื่อว่า XGBoost ซึ่งมักจะใช้สำหรับโจทย์ที่เป็น Regresssion, Time series หรือ Classification ครับ ข้อดีของเจ้า XGBoost ก็คือสามารถให้ความแม่นยำที่ค่อนข้างสูง และเทรนโมเดลได้รวดเร็วครับ
- ส่วน Library ที่ใช้ในการอธิบายการทำงานของโมเดล มีชื่อว่า SHAP ครับ เปเปอร์เพิ่งจะตีพิมพ์ออกมาเมื่อต้นปี 2018 เอง หลายๆคนเลยยังไม่ค่อยรู้จักเท่าไร
วิเคราะห์ข้อมูลเบื้องต้น

นี้คือข้อมูลทั้งหมดที่เรามีครับเป็นข้อมูลรายชั่วโมงจากเดือนมีนา 2016 ถึง มกรา 2019 ทีนี้ลองมาดูเทียบกันปีต่อปีดีกว่าว่าจริงๆแล้วฝุ่นมันเพิ่มขึ้นจริงๆไหม


ภาพด้านบนคือการเทียบ PM2.5 รายวันแบบปีต่อปีครับ ภาพแรกคือเฉลี่ยรายวัน ภาพที่สองคือค่า PM2.5 สูงสุดของวันนั้นๆ สังเกตได้ว่าช่วงที่ฝุ่นเยอะที่สุดคือประมาณเดือนธ.ค.ถึงเดือนมี.ค. และเมื่อดูเฉพาะในเดือนดังกล่าวจะเห็นได้ว่าในปี 2018 นั้นค่า PM2.5 ค่อนข้างจะสูงกว่าปี 2017 ครับ



ถัดมา เคยสงสัยไหมครับ ว่าช่วงไหนของวันที่ฝุ่นเยอะที่สุด ถ้าดูจากรูปด้านบนนี้ จะเห็นเลยครับว่าวันจันทร์ ถึง พุธ ระหว่าง 8 โมงเช้า ถึง 10 โมงเช้า คือช่วงที่ฝุ่นเยอะที่สุดโดยเฉลี่ยครับ ส่วนช่วงที่ฝุ่นน้อยที่สุดคือวันศุกร์ เสาร์ อาทิตย์ ช่วงบ่าย 3 โมงถึง 5 โมงเย็น

ทีนี้เราลองมาดูค่า linear correlation กันครับ สียิ่งเข้มคือแสดงว่ามีผลให้ค่าเป็นบวกมากขึ้น ส่วนสียิ่งอ่อนคือส่งผลให้ค่าลดลงครับ วิธีการดูคือดูเฉพาะแถว PM2.5 จะดูจากด้านบนหรือด้านล่างก็ได้ จะเห็นได้ว่ากล่องที่สีเข้มขึ้นมาเลยคือ pressure, wind_dir_ENE(east-northeast)และ wind_dir_NE(northeast) ส่วนกล่องที่สีอ่อนที่สุดเลยคือ dewpoint(อุณหภูมิจุดน้ำค้าง)
ถ้าลิสออกมาตามลำดับมากไปน้อย และน้อยไปมากก็จะได้ตามนี้ครับ
PM2.5 1.000000
pressure 0.393460
wind_dir_NE 0.164482
wind_dir_NNE 0.140913
wind_dir_ENE 0.135612
wind_dir_NNW 0.109336
wind_dir_North 0.106679
Year 0.101283
wind_dir_NW 0.100891
wind_dir_SE 0.063553
Name: PM2.5, dtype: float64
dewpoint -0.385505
humidity -0.274888
wind_dir_WSW -0.221088
quarter -0.169156
heatindex -0.168391
wind_speed -0.162973
Month -0.160328
wind_dir_degrees -0.160226
dayofyear -0.158906
weekofyear -0.157984เทรนโมเดล ML
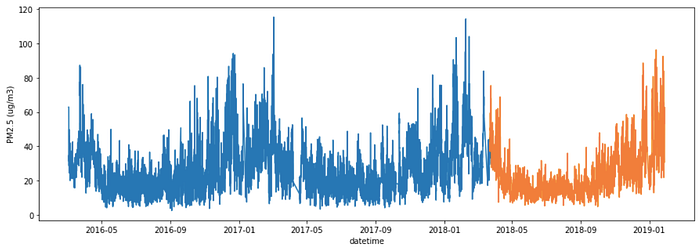
ก่อนอื่นเลยเราก็ต้องแบ่งข้อมูลก่อนสำหรับ Train 70% และ Test 30% ครับ
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=1000,
n_jobs=1, nthread=None, objective='reg:linear', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1)ทีนี้เราก็เทรนโมเดลโดยใช้ XGBoost สำหรับบทความนี้ผมไม่ได้ทำ parameter tuning แต่อย่างใด ก็จะเป็นค่า default ทั้งหมด เพื่อความรวดเร็วครับ
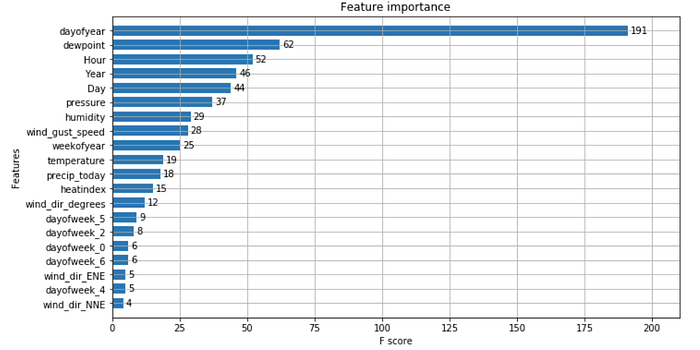
พอเทรนเสร็จเราก็มาดู Feature importance กันครับว่า Feature ไหนที่ส่งผลกับโมเดลบ้าง และส่งผลมากขนาดไหน ถ้าดูจากรูปจะเห็นได้ว่าน้ำหนักส่วนใหญ่ไปลงที่วันของปีสะเป็นส่วนใหญ่ แสดงว่าโมเดลคิดว่าวันในแต่ละปีมีค่าที่ค่อนข้างจะคล้ายกัน
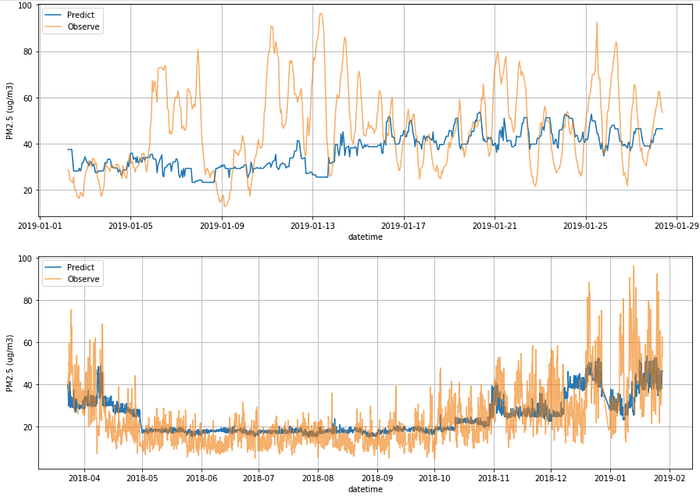
ลองให้โมเดลทำนายค่า PM2.5 ที่เป็น Test set ของเราดูครับ จะเห็นได้ว่าโมเดลของเราไม่แม่นเอาสะเลย สาเหตที่ไม่แม่นเพราะว่าเราไม่ได้ใส่ Lag data หรือข้อมูล PM2.5 ของชั่วโมงก่อนๆที่เราจะทำนายเข้าไปครับ เพราะว่าเป้าหมายหลักของโมเดลนี้คือต้องการดูว่าค่า Feature ตัวอื่นๆจะส่งผลยังไงกับการทำนายบ้าง ซึ่งถ้าใส่ Lag ของชั่วโมงก่อนหน้าเข้าไป โมเดลจะให้น้ำหนักไปที่ค่าของชั่วโมงก่อนหน้ามากเลยครับเพราะว่าทำให้โมเดลมีความแม่นยำสูงสุด
อธิบายโมเดลด้วย SHAP
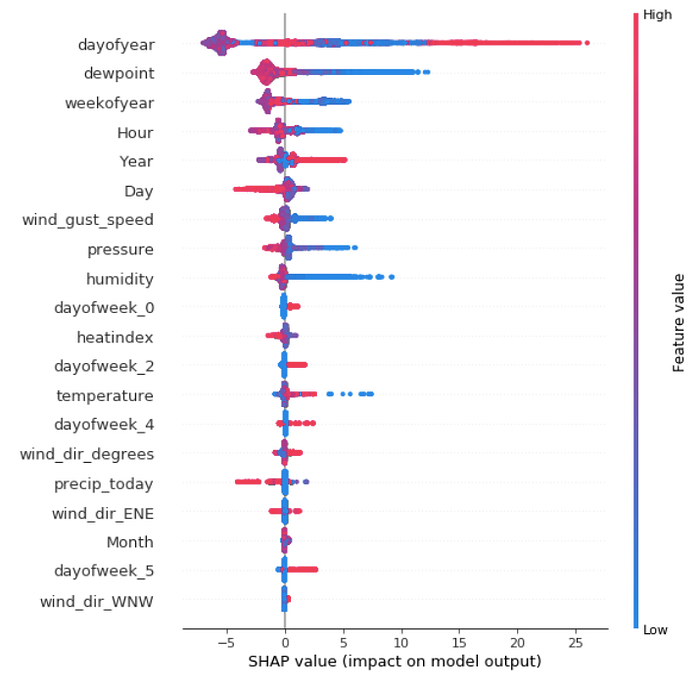
มาถึงส่วนที่สำคัญที่สุดของเราครับ ภาพนี้อธิบายว่า Feature ตัวไหนส่งผลกับการทำนายของโมเดลของเราบ้าง หรืออีกความหมายนึงก็คือตัวแปรไหนที่ทำให้ PM2.5 ของเราสูงขึ้นหรือลดลง ซึ่งถ้าเราเปรียบเทียบกับ linear correlation ที่เราหามาก่อนหน้านี้จะเห็นได้ว่ามีทั้งส่วนที่เหมือนกันและส่วนที่เราค้นพบเพิ่มเติมขึ้นมาครับ วิธีการดูก็ง่ายๆครับ
- ดูแกน 0 ของ SHAP value ก่อน ถ้าเลยไปทางซ้าย แสดงว่าส่งผลลบกับค่า PM2.5 ถ้าเลยไปทางขวา แสดงว่าส่งผลบวก
- ดูสี สีแดงคือเมื่อค่าของ Feature นั้นมีค่าที่สูง และสีฟ้าคือเมื่อมีค่าต่ำ
ตัวอย่าง เช่น dewpoint ที่มีแกนสีฟ้าเลยไปทางขวา แสดงว่าเมื่อ dewpoint มีค่าต่ำจะส่งผลให้ PM2.5 ที่โมเดลทำนายนั้นมีค่าสูง
ที่น่าสนใจคือ dewpoint, wind_gust_speed, pressure, humidity, temperature ครับที่เมื่อตัวแปรเหล่านี้มีค่าต่ำมากๆ โมเดลของเราจะทำนายว่า PM2.5 จะสูงขึ้นครับ ส่วน precip_today(ปริมาณฝนที่ตกวันนั้น) เมื่อมีค่ามาก จะทำให้ผลลัพธ์ที่โมเดลทำนายมีค่าลดลงครับ
*หมายเหตุ correlation ไม่ใช่ causation เราสามารถบอกได้ว่าตัวแปรต่างๆมีความเกี่ยวข้องกัน แต่ไม่สามารถบอกได้ว่าตัวแปรนั้นๆเป็นต้นเหตุให้กับค่าที่ทำนายได้
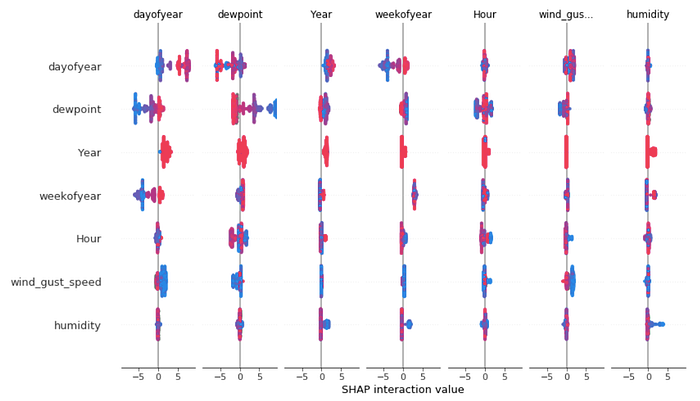
ถ้าเราจับ Feature มาดูเป็นคู่ๆ ก็จะได้ออกมาเป็นแบบนี้ครับ กราฟนี้ดูค่อนข้างที่จะยากนิดนึง ดูภาพด้านล่างที่เป็นการ Plot ออกมาแบบคู่ๆแทนก็ได้ครับ


รูปซ้ายบน: dewpoint ที่ประมาณ 22.5–26 °C ส่งผลลบกับ PM2.5 ตลอดทั้งปี
รูปซ้ายล่าง: wind_gust_speed เมื่อต่ำกว่า 5 km/h จะทำให้ค่า PM2.5 สูงขึ้น และทำให้ค่าลดลงเมื่อมีความเร็วมากกว่า 5 km/h
รูปบนขวา: เมื่อ pressure สูงกว่า 1010 hPa และ dewpoint มีค่าต่ำจะทำให้โมเดลทำนาย PM2.5 ลดลง แต่ถ้า pressure ต่ำกว่า 1010 ก็จะทำให้การทำนายมีค่าสูงขึ้น
รูปขวาล่าง: เมื่อ humidity มากกว่า 60% ก็จะทำให้ PM2.5 ลดลง


รูปซ้ายบน: เมื่อ heat index มากกว่าประมาณ 38 และ temperature สูงก็จะทำให้ PM2.5 มีค่าลดลง
รูปซ้ายล่าง: ช่วง temperature ระหว่าง 15–20°C และ dewpoint ต่ำ จะทำให้ค่า PM2.5 สูงขึ้น ในขณะที่ช่วง 30–35°C มักจะทำให้ค่า PM2.5 สูงขึ้นเสมอ
รูปบนขวา: wind direction degrees ขึ้นอยู่กับช่วงสัปดาห์ของปีในการส่งผล
รูปขวาล่าง: precipitation today ค่อนข้างจะทำให้ PM2.5 ลดลงตลอดทั้งปี แต่สังเกตว่าถ้าฝนตกสะสม 40–55 mm ในหนึ่งวันก็จะทำให้ฝุ่นลดลงเป็นพิเศษครับ
ตัวอย่างการทำนาย
ด้านล่างคือภาพตัวอย่างการทำนายของ 2 ชม.ที่มีค่า PM2.5 มากที่สุด และ 2 ชม.ที่มีค่า PM2.5 น้อยที่สุดครับ จากรูปเราจะเห็นได้ว่าตัวแปรไหนที่ส่งผลบวกให้กับค่า PM2.5 (สีแดง) และตัวแปรไหนที่ส่งผลลบ (สีฟ้า)ให้กับค่า PM2.5 ในการทำนายครับ




จบ
ขอบคุณทุกคนที่อ่านมาถึงตรงนี้นะครับ บทความนี้ก็ใช้เวลาไปทั้งสิ้นประมาณ 10 ชม.ในการเขียนโค้ต บวกกับ 4 ชม.ในการเขียนบทความ สำหรับใครที่ต้องการสคริปหรือข้อมูลก็สามารถดาวโหลดได้จาก Github นี้เลยครับ จะเอาไปลองรันเล่นดูหรือจะพัฒนาโมเดลต่อก็เชิญตามสะดวกเลยครับ หวังว่าบทความนี้จะเป็นประโยชน์ไม่มากก็น้อยสำหรับคนทั่วไปหรือคนที่อยากเป็น data scientist ครับ ขอบคุณมากครับ









